Class SmoothedMovingAverage
- Jump right in for a hands-on
Import
from NitroFE import SmoothedMovingAverage
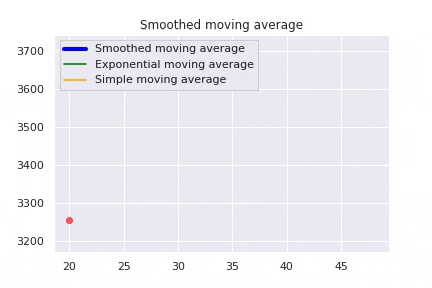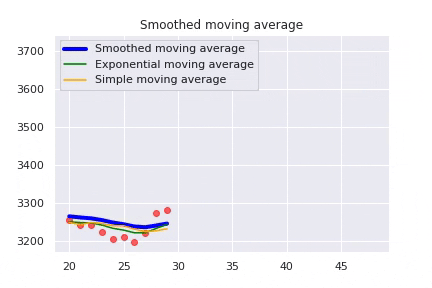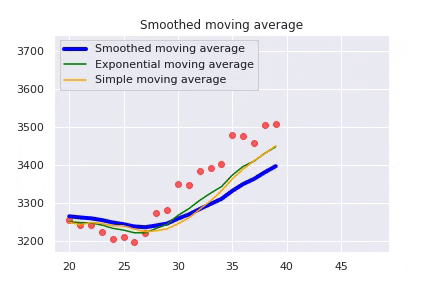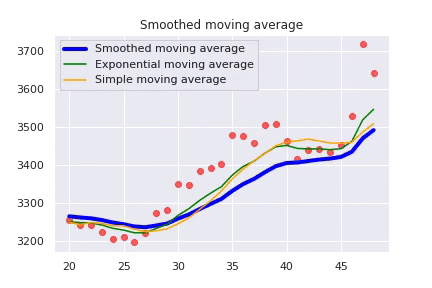
The Smoothed Moving Average (SMMA) is a combination of a SMA and an EMA. It gives the recent values an equal weighting as the historic prices as it takes all available price data into account. The main advantage of a smoothed moving average is that it removes short-term fluctuations, and allows us to view the values trends much easier.
smoothed moving average (SMMA) is calculated as
Methods
Provided dataframe must be in ascending order.
__init__(self, lookback_period=4)
special
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
lookback_period |
int |
Size of the rolling window of lookback , by default 4 |
4 |
Source code in nitrofe\time_based_features\moving_average_features\moving_average_features.py
def __init__(self, lookback_period: int = 4):
"""
Parameters
----------
lookback_period : int, optional
Size of the rolling window of lookback , by default 4
"""
self.lookback_period = lookback_period
fit(self, dataframe, first_fit=True)
For your training/initial fit phase (very first fit) use fit_first=True, and for any production/test implementation pass fit_first=False
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataframe |
Union[pandas.core.frame.DataFrame, pandas.core.series.Series] |
dataframe containing column values to create feature over |
required |
first_fit |
bool |
Moving features require past values for calculation. Use True, when calculating for training data (very first fit) Use False, when calculating for subsequent testing/production data { in which case the values, which were saved during the last phase, will be utilized for calculation }, by default True |
True |
Source code in nitrofe\time_based_features\moving_average_features\moving_average_features.py
def fit(
self,
dataframe: Union[pd.DataFrame, pd.Series],
first_fit: bool = True,
):
"""
For your training/initial fit phase (very first fit) use fit_first=True, and for any production/test implementation pass fit_first=False
Parameters
----------
dataframe : Union[pd.DataFrame, pd.Series]
dataframe containing column values to create feature over
first_fit : bool, optional
Moving features require past values for calculation.
Use True, when calculating for training data (very first fit)
Use False, when calculating for subsequent testing/production data { in which case the values, which
were saved during the last phase, will be utilized for calculation }, by default True
"""
if first_fit:
self._first_object = weighted_window_features()
if isinstance(dataframe, pd.Series):
dataframe = dataframe.to_frame()
sma = pd.DataFrame(
np.zeros(dataframe.shape), columns=dataframe.columns, index=dataframe.index
)
if first_fit:
sma.iloc[self.lookback_period - 1] = (
dataframe.iloc[: (self.lookback_period)].sum() / self.lookback_period
)
else:
sma = pd.concat([self.values_from_last_run, sma])
sma["_iloc"] = np.arange(len(sma))
ll = [x for x in sma.columns if x != "_iloc"]
_start_frame = self.lookback_period if first_fit else 0
_start_sma = self.lookback_period if first_fit else 1
for r1, r2 in zip(
dataframe[_start_frame:].iterrows(), sma[_start_sma:].iterrows()
):
previous_kama = sma[sma["_iloc"] == (r2[1]["_iloc"] - 1)][ll]
sma.loc[sma["_iloc"] == r2[1]["_iloc"], ll] = (
(previous_kama * (self.lookback_period - 1) + r1[1])
/ self.lookback_period
).values[0]
res = sma[ll] if first_fit else sma.iloc[1:][ll]
self.values_from_last_run = res.iloc[-1:]
return res
References
- chartmill, "The SMOOTHED MOVING AVERAGE", https://www.chartmill.com/documentation/technical-analysis-indicators/217-MOVING-AVERAGES-%7C-The-Smoothed-Moving-Average-%28SMMA%29