Class SeriesWeightedAverage
- Jump right in for a hands-on
Import
from NitroFE import SeriesWeightedAverage
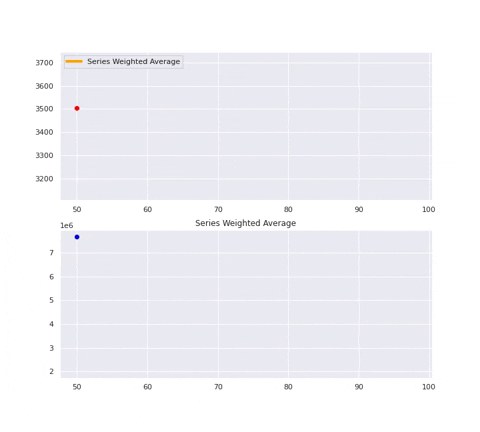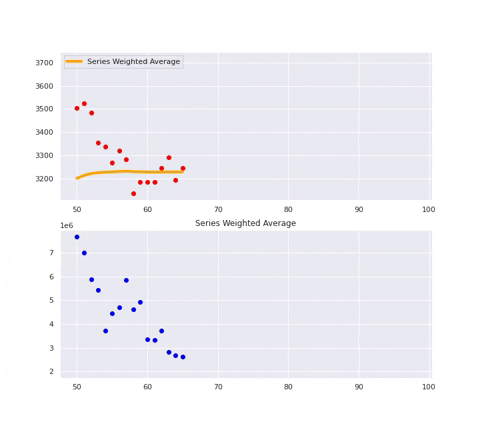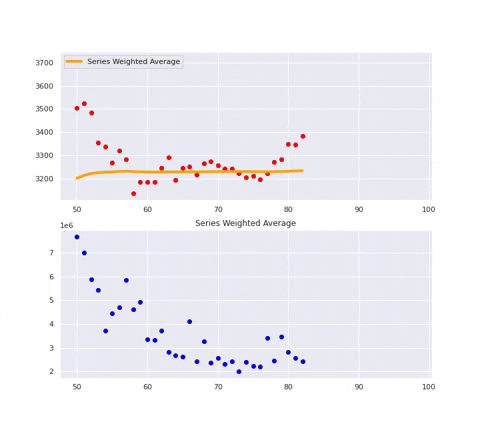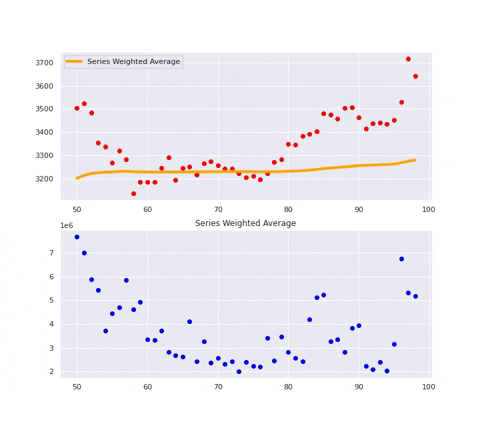
series_weighted_average This feature is an implementation of volume weighted moving average
\[
series\_weighted\_average = \frac{\sum (dataframe * dataframe\_for\_weight) }{\sum dataframe\_for\_weight }
\]
Methods
fit(self, dataframe, dataframe_for_weight, first_fit=True)
For your training/initial fit phase (very first fit) use fit_first=True, and for any production/test implementation pass fit_first=False
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
dataframe |
Union[pandas.core.frame.DataFrame, pandas.core.series.Series] |
dataframe containing column values |
required |
dataframe_for_weight |
Union[pandas.core.frame.DataFrame, pandas.core.series.Series] |
dataframe containing column values |
required |
first_fit |
bool |
Indicator features require past values for calculation. Use True, when calculating for training data (very first fit) Use False, when calculating for subsequent testing/production data { in which case the values, which were saved during the last phase, will be utilized for calculation }, by default True |
True |
Source code in nitrofe\time_based_features\indicator_features\_seriesweightedaverage.py
def fit(
self,
dataframe: Union[pd.DataFrame, pd.Series],
dataframe_for_weight: Union[pd.DataFrame, pd.Series],
first_fit: bool = True,
):
"""
For your training/initial fit phase (very first fit) use fit_first=True, and for any production/test implementation pass fit_first=False
Parameters
----------
dataframe : Union[pd.DataFrame, pd.Series]
dataframe containing column values
dataframe_for_weight : Union[pd.DataFrame, pd.Series]
dataframe containing column values
first_fit : bool, optional
Indicator features require past values for calculation.
Use True, when calculating for training data (very first fit)
Use False, when calculating for subsequent testing/production data { in which case the values, which
were saved during the last phase, will be utilized for calculation }, by default True
"""
if isinstance(dataframe, pd.Series):
dataframe = dataframe.to_frame()
if isinstance(dataframe_for_weight, pd.Series):
dataframe_for_weight = dataframe_for_weight.to_frame()
multiplication_res = (
pd.DataFrame(
np.multiply(dataframe.values, dataframe_for_weight.values),
columns=dataframe.columns,
)
if first_fit
else pd.concat(
[
self.multiplication_values_from_last_run,
pd.DataFrame(
np.multiply(dataframe.values, dataframe_for_weight.values),
columns=dataframe.columns,
),
]
)
)
if not first_fit:
dataframe_for_weight = pd.concat(
[self.values_from_last_run, dataframe_for_weight]
)
cumilative_res = dataframe_for_weight.expanding().sum()
cumilative_multiplication_res = multiplication_res.expanding().sum()
self.multiplication_values_from_last_run = cumilative_multiplication_res.iloc[
-1:
]
cumilative_multiplication_res = (
cumilative_multiplication_res.iloc[1:]
if (not first_fit)
else cumilative_multiplication_res
)
cumilative_res = cumilative_res.iloc[1:] if (not first_fit) else cumilative_res
dataframe_for_weight = (
dataframe_for_weight.iloc[1:] if (not first_fit) else dataframe_for_weight
)
res = pd.DataFrame(
cumilative_multiplication_res.values / (cumilative_res.values)
)
self.values_from_last_run = cumilative_res.iloc[-1:]
return res
References
- investopedia, "Volume-Weighted Average Price", https://www.investopedia.com/terms/v/vwap.asp